



MAGICでXQuery (2)
前回は、MAGICでXQueryを使う意義と価値について説明した。
今回は、SQL ServerのManagement Studio(以下「SSMS」)を使い、XMLデータを格納するテーブルの作成、XMLデータの取り込み、取り込んだXMLのアクセス方法について説明したい。
SSMSの起動
MAGICソース管理ツールSMSYSで作成したデータベースがあればそれをSSMSで指定し、クエリウインドウを開く。
- SSMSを開き、「サーバーへの接続」を行う
- [データベース」を展開し、目的のデータベースを選択する
- オブジェクト エクスプローラーで右クリックし、 [新しいクエリ] を選択
テーブルの作成
テーブルは単純にプログラムのIDを格納するカラムとXMLファイルを格納するカラム(カラムタイプを「xml」として指定)で作成する。
クエリウインドウに次のクエリを貼り付ける。
CREATE TABLE XMLTEST
(
OBJ_ID int NOT NULL,
XMLCOL xml NULL,
)
GO
データの挿入
行挿入のクエリ文を実行する。
XMLデータのインポートには OPENROWSET 関数を使用。
クエリウインドウに次のクエリを貼り付ける。(OBJ_IDの値、物理ファイル名は要修正)
INSERT INTO
XMLTEST (
OBJ_ID,
XMLCOL
)
VALUES (
2,
( SELECT * FROM OPENROWSET( BULK 'C:\PJ_PATH\PJ1\Source\Prg_2.xml', SINGLE_BLOB) AS X )
)
GO
データの更新
行挿入と同様、行更新のクエリ文を実行する。
クエリウインドウに次のクエリを貼り付ける。(OBJ_IDの値、物理ファイル名は要修正)
UPDATE
XMLTEST
SET
XMLCOL = ( SELECT * FROM OPENROWSET(BULK 'C:\PJ_PATH\PJ1\Source\Prg_2.xml', SINGLE_BLOB ) AS X )
WHERE
OBJ_ID = 2
GO
データの照会 (1)
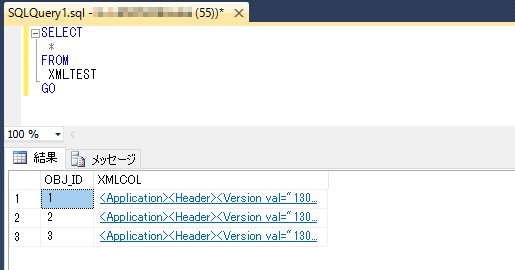
まず、「SELECT *」で全てのカラムを表示してみる。
次のクエリをクエリウインドウに貼り付け、「実行」してみよう!
SELECT
*
FROM
XMLTEST
GO
結果ウインドウに検索結果が表示される。
カラム「XMLCOL」にXMLデータが登録されていることが確認できる。
(クリックするとソース内容が確認可)

データの照会 (2)
次にXMLデータ中の特定の要素やその属性の値を読み取ってみよう。
value() メソッドを使用することにより、XMLに対してXQueryを実行することが可能。(返ってくる値はスカラー値)
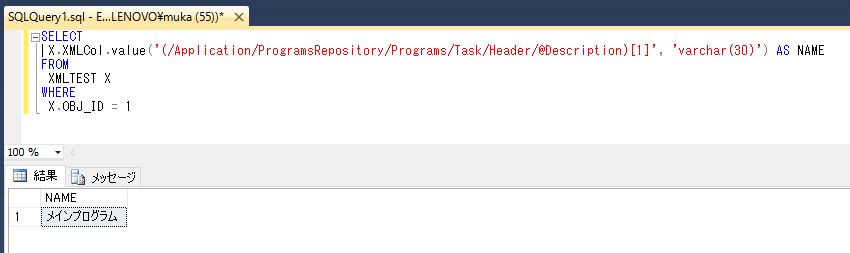
試しにプログラムの名称を取得してみる。
クエリウインドウに次のクエリを貼り付ける。
SELECT
X.XMLCol.value('(/Application/ProgramsRepository/Programs/Task/Header/@Description)[1]', 'varchar(30)') AS NAME
FROM
XMLTEST X
WHERE
X.OBJ_ID = 1
結果ウインドウに検索結果が表示される。
通常のテーブルカラムと同じようにスカラー値としてのプログラム名が出力されていることが確認できる。

データの照会 (3)
次は再帰的にネストされた構造のXMLデータを読んでみよう。
そう、これはまさにMAGICのタスクツリーのようなイメージである。
テスト用として下図のような階層関係を持つプログラムを作成する。各々のタスクは空のままで構わない。

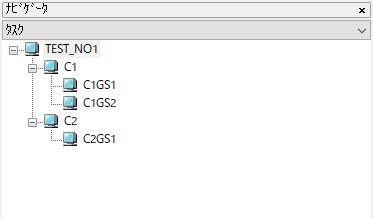
下図に作成されたプログラムのソースを表示する。
(赤枠線で囲った箇所はそれぞれのタスク要素を示す)


query () メソッドはxmlデータ型のクエリ結果を返す。
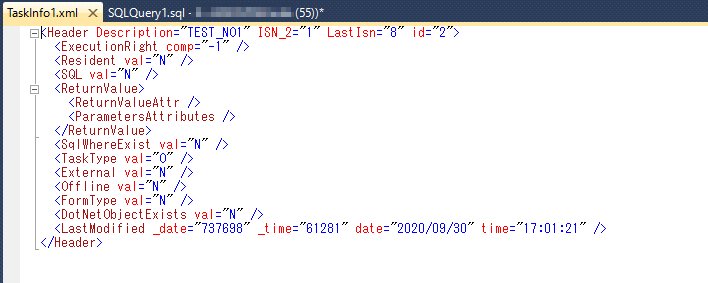
例えば下記のクエリを実行すると、ルートタスクのHeader要素(下位のデータを含む)を抜き出すことができる。
SELECT
X.XMLCol.query('/Application/ProgramsRepository/Programs/Task/Header') AS TaskInfo
FROM
XMLTEST X
WHERE
X.OBJ_ID = 2

今度は先のクエリのXPATHの「Task」の先頭に「/」を1文字加えてみる。
つまり「Programs/Task/Header」を「Programs//Task/Header」に変更するのだ。
SELECT
X.XMLCol.query('/Application/ProgramsRepository/Programs//Task/Header') AS TaskInfo
FROM
XMLTEST X
WHERE
X.OBJ_ID = 2
今度は、すべてのタスクのHeader要素を抜き出すことができた。


しかし、これでは出力結果に親の要素が無く、正しいXMLデータとして処理ができない。
下記のように変更してみよう。
SELECT
X.XMLCol.query('
<TASKS>
{/Application/ProgramsRepository/Programs//Task/Header}
</TASKS>
') AS TaskInfo
FROM
XMLTEST X
WHERE
X.OBJ_ID = 2

FLWORステートメントの「for」と「return」を使うと下記のように記載することも可能。
SELECT
X.XMLCol.query('
<TASKS>
{for $e in /Application/ProgramsRepository/Programs//Task/Header
return $e
}
</TASKS>
') AS TaskInfo
FROM
XMLTEST X
WHERE
X.OBJ_ID = 2
今度は、親子関係が分かるようにするために、親のタスクのIDを埋め込んでみる。
「TASKS」配下に「TASK」という要素を出力
「TASK」要素の配下に「Header」要素を出力
親要素のID($e/../../Header/@ISN_2)を取得(letで変数$aに値をセットしておく)
「TASK」の属性「Parent」に取得した親要素のIDを出力
結果、下記のようなクエリに変更。
SELECT
X.XMLCol.query('
<TASKS>
{for $e in /Application/ProgramsRepository/Programs//Task/Header
let $a := $e/../../Header/@ISN_2
return <TASK Parent="{$a}">{$e}</TASK>
}
</TASKS>
') AS TaskInfo
FROM
XMLTEST X
WHERE
X.OBJ_ID = 2
出力結果は下図のとおり。

最後に必要な情報のみを自由な形で出力する例を紹介する。
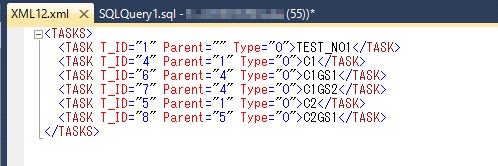
下記のクエリは、タスクのID、親タスクのID、タスクのタイプをそれぞれ属性として、またタスクの名称は要素のテキストとして出力している例である。
タスクの名称($e/Header/@Description)は属性値であるが、これをData 関数を使用してテキストノードに変換して出力している。
SELECT
X.XMLCOL.query('
<TASKS>
{for $e in /Application/ProgramsRepository/Programs//Task
let $i := $e/Header/@ISN_2
let $n := data($e/Header/@Description)
let $p := $e/../Header/@ISN_2
let $t := $e/Header/TaskType/@val
return <TASK T_ID="{$i}" Parent="{$p}" Type="{$t}">{$n}</TASK>}
</TASKS>
') AS XML
FROM
XMLTEST X
WHERE
X.OBJ_ID = 2
出力結果は下図のとおり。

© 2018-2022 Eternal Design Corp. All rights reserved.